
This is a cheat sheet of my lecture “Why Am I So Obsessed with Evals”. There’s a lot of content out there and most of it is messy/too general. So here’s my take on it, straight up. If you weren’t at my lecture and want to hear more, let me know.
The Promise
GenAI creates the feeling that it’s incredibly easy to do things. Yeah, it’s easy to build something that works 90% of the time, but the distance to 99% or 100% is hard - and I believe that Evals can enable us to get there.
So what exactly am I talking about when I talk about Evals?
It’s about a collection of small tests that check the output of the model. They can be:
-
Code Evals - for example, ensuring that the output is JSON, length, number of answers, etc. Simple and precise.
-
LLM-as-a-Judge - asking one model to judge the output of another model. You want it to be binary, and the more specific, the better.
- Good question: “Does the answer contain medical information? Answer yes/no”
- Less good question: “Rate how accurate the answer is from 1-5”
-
Evals for Evaluators - evaluating your evaluators. Basically you compare what your LLM-as-a-Judge says against actual human-labeled data. For example, “Does the model’s answer match what our domain expert said?”
How do we start?
Before we begin implementing an AI model in a product, it’s critical to define (like any project) - what success will look like, what failures will look like, and what the risks are. For example, if we want to implement a support chatbot - we really, really don’t want it to give customers information about other customers. So you really dig deep and think it through.
This could be a collection of good/bad examples that domain experts tagged, or a really detailed system prompt.
But from painful experience—this is almost never enough. You start and discover edge cases you didn’t think of, the model finds cases you missed so you add them to the dataset, the model behaves differently than expected so you update the prompt. It makes sense. It’s impossible to think of everything beforehand.
So what do we do?
I recently found an excellent framework of two researchers, which in my opinion simply exploits a human weakness: we’re not good at thinking of everything beforehand, but we really love identifying the mistakes of others.
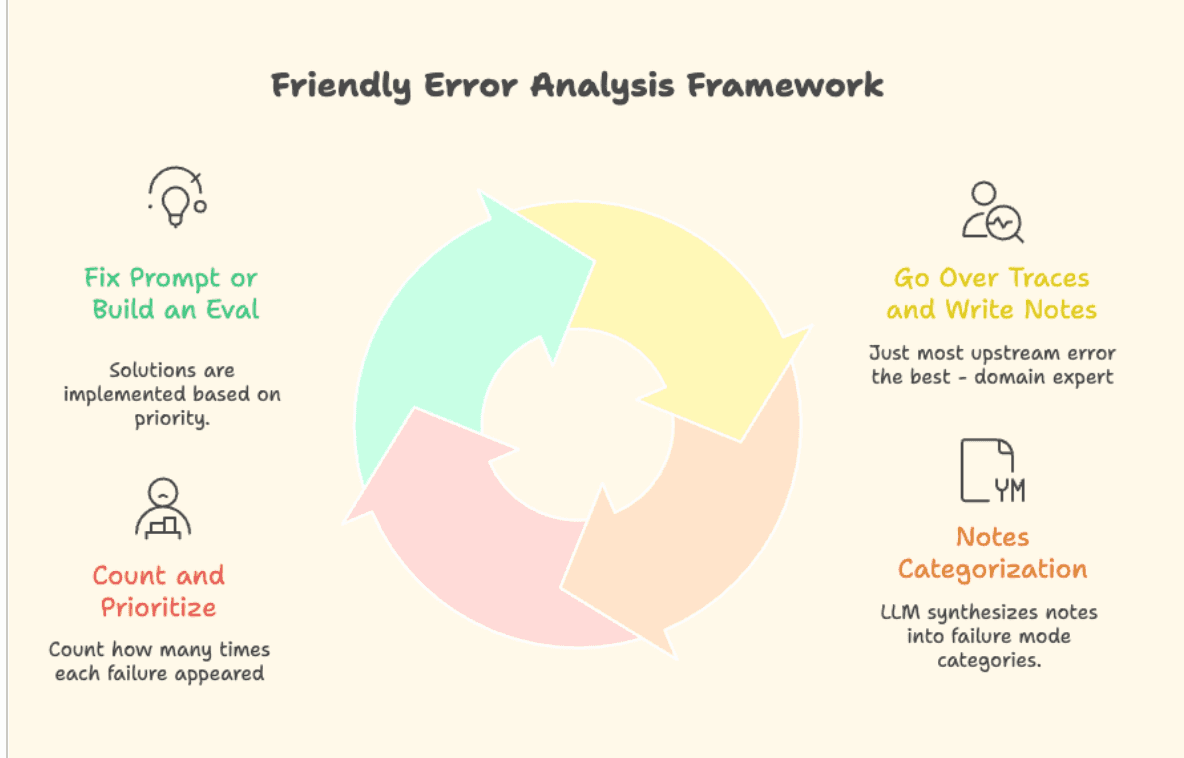
The Simple Idea
-
Go through your data. In our case, that’s traces of the model (all the inputs and outputs) from our observability system. When you identify a problem, write what’s wrong in a comment in the system itself. Go through at least 100 examples.
-
Take all the notes, put them in some LLM, and ask it to cluster them by types of errors (or failure modes), and also count how many notes appear in each cluster.
-
We actually got a prioritization of failure modes! For each one of them, we can build an eval, change the system prompt or the ground truth, or just ignore it.
You build an eval if you want to use it during development—either as monitoring that alerts you, or as a guardrail that blocks bad answers.
Once you have a set of evals that work in real time—it basically works like CI/CD. You can make changes to your whole system without panicking that everything will break.
- We do this process iteratively - once a week, we go through the data. Even half an hour like that works wonders.
In my opinion, all observability systems are pretty similar for this purpose, and they all let you implement LLM-as-a-Judge. I use Langfuse, lots of people swear by Langsmith, and I hear Braintrust is solid too.
Some answers to questions from the audience (updates with each lecture)
-
How do you test different prompts or try to choose between two different models? Exactly as we described. If we built a set of evals, we can simply run an a/b test and see who performs better against the evals we built. Science!
-
What do you do when two different people tag errors differently? Yeah, super common in data science. Common solutions: only one person is the arbiter, or you average between several taggings.
So why am I really so obsessed with Evals?
The balance in many professions is shifting from creation to verification.
Build a solid set of evals through iteration and real friction with your data—and suddenly you can move fast, break things without panicking, test different models and prompts without guessing. That’s a moat. That’s how you get from 90% to 99%.